Timeseries classification from scratch
Source:vignettes/examples/timeseries/timeseries_classification_from_scratch.Rmd
timeseries_classification_from_scratch.RmdIntroduction
This example shows how to do timeseries classification from scratch, starting from raw CSV timeseries files on disk. We demonstrate the workflow on the FordA dataset from the UCR/UEA archive.
Setup
library(keras3)
use_backend("jax")Load the data: the FordA dataset
Dataset description
The dataset we are using here is called FordA. The data comes from the UCR archive. The dataset contains 3601 training instances and another 1320 testing instances. Each timeseries corresponds to a measurement of engine noise captured by a motor sensor. For this task, the goal is to automatically detect the presence of a specific issue with the engine. The problem is a balanced binary classification task. The full description of this dataset can be found here.
Read the TSV data
We will use the FordA_TRAIN file for training and the
FordA_TEST file for testing. The simplicity of this dataset
allows us to demonstrate effectively how to use ConvNets for timeseries
classification. In this file, the first column corresponds to the
label.
get_data <- function(path) {
if(path |> startsWith("https://"))
path <- get_file(origin = path) # cache file locally
data <- readr::read_tsv(
path, col_names = FALSE,
# Each row is: one integer (the label),
# followed by 500 doubles (the timeseries)
col_types = paste0("i", strrep("d", 500))
)
y <- as.matrix(data[[1]])
x <- as.matrix(data[,-1])
dimnames(x) <- dimnames(y) <- NULL
list(x, y)
}
root_url <- "https://raw.githubusercontent.com/hfawaz/cd-diagram/master/FordA/"
c(x_train, y_train) %<-% get_data(paste0(root_url, "FordA_TRAIN.tsv"))
c(x_test, y_test) %<-% get_data(paste0(root_url, "FordA_TEST.tsv"))
str(keras3:::named_list(
x_train, y_train,
x_test, y_test
))## List of 4
## $ x_train: num [1:3601, 1:500] -0.797 0.805 0.728 -0.234 -0.171 ...
## $ y_train: int [1:3601, 1] -1 1 -1 -1 -1 1 1 1 1 1 ...
## $ x_test : num [1:1320, 1:500] -0.14 0.334 0.717 1.24 -1.159 ...
## $ y_test : int [1:1320, 1] -1 -1 -1 1 -1 1 -1 -1 1 1 ...Visualize the data
Here we visualize one timeseries example for each class in the dataset.
plot(NULL, main = "Timeseries Data",
xlab = "Timepoints", ylab = "Values",
xlim = c(1, ncol(x_test)),
ylim = range(x_test))
grid()
lines(x_test[match(-1, y_test), ], col = "blue")
lines(x_test[match( 1, y_test), ], col = "red")
legend("topright", legend=c("label -1", "label 1"), col=c("blue", "red"), lty=1)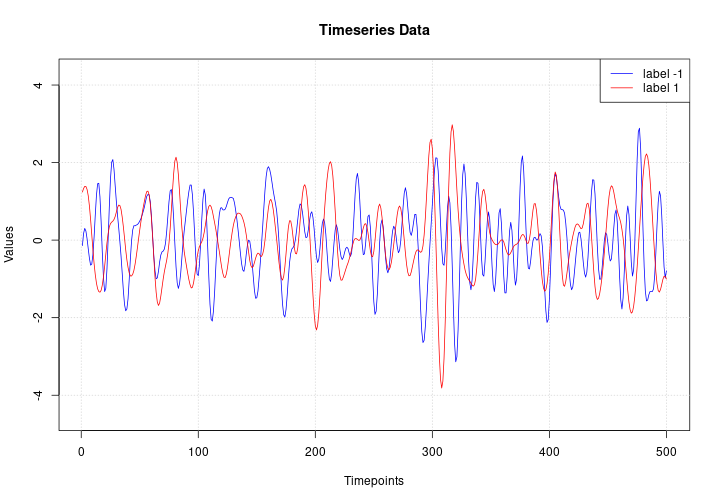
Standardize the data
Our timeseries are already in a single length (500). However, their values are usually in various ranges. This is not ideal for a neural network; in general we should seek to make the input values normalized. For this specific dataset, the data is already z-normalized: each timeseries sample has a mean equal to zero and a standard deviation equal to one. This type of normalization is very common for timeseries classification problems, see Bagnall et al. (2016).
Note that the timeseries data used here are univariate, meaning we only have one channel per timeseries example. We will therefore transform the timeseries into a multivariate one with one channel using a simple reshaping via numpy. This will allow us to construct a model that is easily applicable to multivariate time series.
Finally, in order to use
sparse_categorical_crossentropy, we will have to count the
number of classes beforehand.
Now we shuffle the training set because we will be using the
validation_split option later when training.
c(x_train, y_train) %<-% listarrays::shuffle_rows(x_train, y_train)
# idx <- sample.int(nrow(x_train))
# x_train %<>% .[idx,, ,drop = FALSE]
# y_train %<>% .[idx, ,drop = FALSE]Standardize the labels to positive integers. The expected labels will then be 0 and 1.
y_train[y_train == -1L] <- 0L
y_test[y_test == -1L] <- 0LBuild a model
We build a Fully Convolutional Neural Network originally proposed in this paper. The implementation is based on the TF 2 version provided here. The following hyperparameters (kernel_size, filters, the usage of BatchNorm) were found via random search using KerasTuner.
make_model <- function(input_shape) {
inputs <- keras_input(input_shape)
outputs <- inputs |>
# conv1
layer_conv_1d(filters = 64, kernel_size = 3, padding = "same") |>
layer_batch_normalization() |>
layer_activation_relu() |>
# conv2
layer_conv_1d(filters = 64, kernel_size = 3, padding = "same") |>
layer_batch_normalization() |>
layer_activation_relu() |>
# conv3
layer_conv_1d(filters = 64, kernel_size = 3, padding = "same") |>
layer_batch_normalization() |>
layer_activation_relu() |>
# pooling
layer_global_average_pooling_1d() |>
# final output
layer_dense(num_classes, activation = "softmax")
keras_model(inputs, outputs)
}
model <- make_model(input_shape = dim(x_train)[-1])
model## Model: "functional"
## ┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━┓
## ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Trai… ┃
## ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━┩
## │ input_layer (InputLayer) │ (None, 500, 1) │ 0 │ - │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ conv1d (Conv1D) │ (None, 500, 64) │ 256 │ Y │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ batch_normalization │ (None, 500, 64) │ 256 │ Y │
## │ (BatchNormalization) │ │ │ │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ re_lu (ReLU) │ (None, 500, 64) │ 0 │ - │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ conv1d_1 (Conv1D) │ (None, 500, 64) │ 12,352 │ Y │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ batch_normalization_1 │ (None, 500, 64) │ 256 │ Y │
## │ (BatchNormalization) │ │ │ │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ re_lu_1 (ReLU) │ (None, 500, 64) │ 0 │ - │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ conv1d_2 (Conv1D) │ (None, 500, 64) │ 12,352 │ Y │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ batch_normalization_2 │ (None, 500, 64) │ 256 │ Y │
## │ (BatchNormalization) │ │ │ │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ re_lu_2 (ReLU) │ (None, 500, 64) │ 0 │ - │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ global_average_pooling1d │ (None, 64) │ 0 │ - │
## │ (GlobalAveragePooling1D) │ │ │ │
## ├─────────────────────────────┼───────────────────────┼────────────┼───────┤
## │ dense (Dense) │ (None, 2) │ 130 │ Y │
## └─────────────────────────────┴───────────────────────┴────────────┴───────┘
## Total params: 25,858 (101.01 KB)
## Trainable params: 25,474 (99.51 KB)
## Non-trainable params: 384 (1.50 KB)
plot(model, show_shapes = TRUE)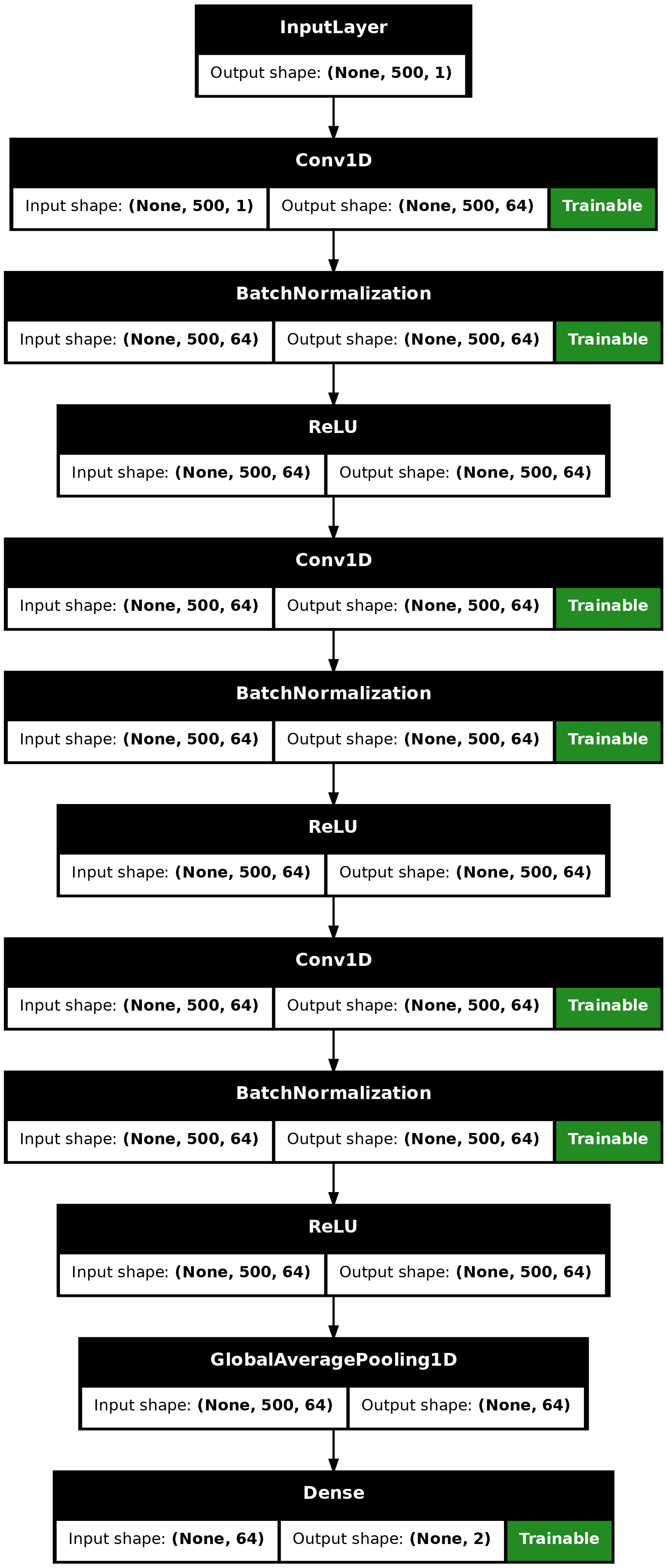
plot of chunk unnamed-chunk-9
Train the model
epochs <- 500
batch_size <- 32
callbacks <- c(
callback_model_checkpoint(
"best_model.keras", save_best_only = TRUE,
monitor = "val_loss"
),
callback_reduce_lr_on_plateau(
monitor = "val_loss", factor = 0.5,
patience = 20, min_lr = 0.0001
),
callback_early_stopping(
monitor = "val_loss", patience = 50,
verbose = 1
)
)
model |> compile(
optimizer = "adam",
loss = "sparse_categorical_crossentropy",
metrics = "sparse_categorical_accuracy"
)
history <- model |> fit(
x_train, y_train,
batch_size = batch_size,
epochs = epochs,
callbacks = callbacks,
validation_split = 0.2
)## Epoch 1/500
## 90/90 - 3s - 33ms/step - loss: 0.5333 - sparse_categorical_accuracy: 0.7194 - val_loss: 0.7873 - val_sparse_categorical_accuracy: 0.4896 - learning_rate: 0.0010
## Epoch 2/500
## 90/90 - 0s - 2ms/step - loss: 0.4811 - sparse_categorical_accuracy: 0.7594 - val_loss: 0.8349 - val_sparse_categorical_accuracy: 0.4896 - learning_rate: 0.0010
## Epoch 3/500
## 90/90 - 0s - 2ms/step - loss: 0.4633 - sparse_categorical_accuracy: 0.7649 - val_loss: 1.0604 - val_sparse_categorical_accuracy: 0.4896 - learning_rate: 0.0010
## Epoch 4/500
## 90/90 - 0s - 2ms/step - loss: 0.4129 - sparse_categorical_accuracy: 0.7969 - val_loss: 0.8687 - val_sparse_categorical_accuracy: 0.4910 - learning_rate: 0.0010
## Epoch 5/500
## 90/90 - 0s - 2ms/step - loss: 0.4186 - sparse_categorical_accuracy: 0.7847 - val_loss: 0.5925 - val_sparse_categorical_accuracy: 0.6546 - learning_rate: 0.0010
## Epoch 6/500
## 90/90 - 0s - 2ms/step - loss: 0.3974 - sparse_categorical_accuracy: 0.8097 - val_loss: 0.5666 - val_sparse_categorical_accuracy: 0.6616 - learning_rate: 0.0010
## Epoch 7/500
## 90/90 - 0s - 2ms/step - loss: 0.3891 - sparse_categorical_accuracy: 0.8167 - val_loss: 0.9860 - val_sparse_categorical_accuracy: 0.6449 - learning_rate: 0.0010
## Epoch 8/500
## 90/90 - 0s - 2ms/step - loss: 0.3743 - sparse_categorical_accuracy: 0.8198 - val_loss: 0.4093 - val_sparse_categorical_accuracy: 0.7795 - learning_rate: 0.0010
## Epoch 9/500
## 90/90 - 0s - 1ms/step - loss: 0.3662 - sparse_categorical_accuracy: 0.8309 - val_loss: 0.4321 - val_sparse_categorical_accuracy: 0.7698 - learning_rate: 0.0010
## Epoch 10/500
## 90/90 - 0s - 1ms/step - loss: 0.3585 - sparse_categorical_accuracy: 0.8299 - val_loss: 0.4278 - val_sparse_categorical_accuracy: 0.7920 - learning_rate: 0.0010
## Epoch 11/500
## 90/90 - 0s - 1ms/step - loss: 0.3726 - sparse_categorical_accuracy: 0.8243 - val_loss: 0.8419 - val_sparse_categorical_accuracy: 0.5978 - learning_rate: 0.0010
## Epoch 12/500
## 90/90 - 0s - 2ms/step - loss: 0.3599 - sparse_categorical_accuracy: 0.8313 - val_loss: 0.3828 - val_sparse_categorical_accuracy: 0.8377 - learning_rate: 0.0010
## Epoch 13/500
## 90/90 - 0s - 1ms/step - loss: 0.3351 - sparse_categorical_accuracy: 0.8531 - val_loss: 0.5018 - val_sparse_categorical_accuracy: 0.7309 - learning_rate: 0.0010
## Epoch 14/500
## 90/90 - 0s - 2ms/step - loss: 0.3314 - sparse_categorical_accuracy: 0.8545 - val_loss: 0.3449 - val_sparse_categorical_accuracy: 0.8488 - learning_rate: 0.0010
## Epoch 15/500
## 90/90 - 0s - 1ms/step - loss: 0.3224 - sparse_categorical_accuracy: 0.8566 - val_loss: 1.4916 - val_sparse_categorical_accuracy: 0.5187 - learning_rate: 0.0010
## Epoch 16/500
## 90/90 - 0s - 2ms/step - loss: 0.3238 - sparse_categorical_accuracy: 0.8632 - val_loss: 0.5534 - val_sparse_categorical_accuracy: 0.6865 - learning_rate: 0.0010
## Epoch 17/500
## 90/90 - 0s - 2ms/step - loss: 0.3083 - sparse_categorical_accuracy: 0.8649 - val_loss: 0.6767 - val_sparse_categorical_accuracy: 0.6546 - learning_rate: 0.0010
## Epoch 18/500
## 90/90 - 0s - 1ms/step - loss: 0.3032 - sparse_categorical_accuracy: 0.8642 - val_loss: 0.3891 - val_sparse_categorical_accuracy: 0.7739 - learning_rate: 0.0010
## Epoch 19/500
## 90/90 - 0s - 1ms/step - loss: 0.2988 - sparse_categorical_accuracy: 0.8708 - val_loss: 0.6758 - val_sparse_categorical_accuracy: 0.7198 - learning_rate: 0.0010
## Epoch 20/500
## 90/90 - 0s - 1ms/step - loss: 0.2936 - sparse_categorical_accuracy: 0.8785 - val_loss: 0.6900 - val_sparse_categorical_accuracy: 0.6644 - learning_rate: 0.0010
## Epoch 21/500
## 90/90 - 0s - 2ms/step - loss: 0.2824 - sparse_categorical_accuracy: 0.8792 - val_loss: 0.3200 - val_sparse_categorical_accuracy: 0.8544 - learning_rate: 0.0010
## Epoch 22/500
## 90/90 - 0s - 1ms/step - loss: 0.2934 - sparse_categorical_accuracy: 0.8743 - val_loss: 0.4334 - val_sparse_categorical_accuracy: 0.7642 - learning_rate: 0.0010
## Epoch 23/500
## 90/90 - 0s - 1ms/step - loss: 0.2795 - sparse_categorical_accuracy: 0.8878 - val_loss: 0.3997 - val_sparse_categorical_accuracy: 0.7920 - learning_rate: 0.0010
## Epoch 24/500
## 90/90 - 0s - 2ms/step - loss: 0.2753 - sparse_categorical_accuracy: 0.8882 - val_loss: 0.2741 - val_sparse_categorical_accuracy: 0.8946 - learning_rate: 0.0010
## Epoch 25/500
## 90/90 - 0s - 1ms/step - loss: 0.2646 - sparse_categorical_accuracy: 0.8941 - val_loss: 0.2833 - val_sparse_categorical_accuracy: 0.8613 - learning_rate: 0.0010
## Epoch 26/500
## 90/90 - 0s - 1ms/step - loss: 0.3049 - sparse_categorical_accuracy: 0.8632 - val_loss: 0.3628 - val_sparse_categorical_accuracy: 0.8363 - learning_rate: 0.0010
## Epoch 27/500
## 90/90 - 0s - 1ms/step - loss: 0.2644 - sparse_categorical_accuracy: 0.8990 - val_loss: 0.2946 - val_sparse_categorical_accuracy: 0.8863 - learning_rate: 0.0010
## Epoch 28/500
## 90/90 - 0s - 2ms/step - loss: 0.2790 - sparse_categorical_accuracy: 0.8840 - val_loss: 0.7881 - val_sparse_categorical_accuracy: 0.6782 - learning_rate: 0.0010
## Epoch 29/500
## 90/90 - 0s - 1ms/step - loss: 0.2637 - sparse_categorical_accuracy: 0.8865 - val_loss: 0.2872 - val_sparse_categorical_accuracy: 0.8821 - learning_rate: 0.0010
## Epoch 30/500
## 90/90 - 0s - 1ms/step - loss: 0.2593 - sparse_categorical_accuracy: 0.8882 - val_loss: 0.3613 - val_sparse_categorical_accuracy: 0.8460 - learning_rate: 0.0010
## Epoch 31/500
## 90/90 - 0s - 1ms/step - loss: 0.2634 - sparse_categorical_accuracy: 0.8889 - val_loss: 0.3513 - val_sparse_categorical_accuracy: 0.8405 - learning_rate: 0.0010
## Epoch 32/500
## 90/90 - 0s - 2ms/step - loss: 0.2576 - sparse_categorical_accuracy: 0.8917 - val_loss: 0.2520 - val_sparse_categorical_accuracy: 0.8877 - learning_rate: 0.0010
## Epoch 33/500
## 90/90 - 0s - 2ms/step - loss: 0.2389 - sparse_categorical_accuracy: 0.9066 - val_loss: 0.4826 - val_sparse_categorical_accuracy: 0.7393 - learning_rate: 0.0010
## Epoch 34/500
## 90/90 - 0s - 1ms/step - loss: 0.2340 - sparse_categorical_accuracy: 0.9073 - val_loss: 0.3814 - val_sparse_categorical_accuracy: 0.8031 - learning_rate: 0.0010
## Epoch 35/500
## 90/90 - 0s - 2ms/step - loss: 0.2519 - sparse_categorical_accuracy: 0.8941 - val_loss: 0.2509 - val_sparse_categorical_accuracy: 0.8849 - learning_rate: 0.0010
## Epoch 36/500
## 90/90 - 0s - 2ms/step - loss: 0.2356 - sparse_categorical_accuracy: 0.9087 - val_loss: 0.3341 - val_sparse_categorical_accuracy: 0.8585 - learning_rate: 0.0010
## Epoch 37/500
## 90/90 - 0s - 1ms/step - loss: 0.2347 - sparse_categorical_accuracy: 0.9066 - val_loss: 0.4274 - val_sparse_categorical_accuracy: 0.7781 - learning_rate: 0.0010
## Epoch 38/500
## 90/90 - 0s - 1ms/step - loss: 0.2298 - sparse_categorical_accuracy: 0.9118 - val_loss: 0.5180 - val_sparse_categorical_accuracy: 0.7573 - learning_rate: 0.0010
## Epoch 39/500
## 90/90 - 0s - 1ms/step - loss: 0.2333 - sparse_categorical_accuracy: 0.9076 - val_loss: 0.3106 - val_sparse_categorical_accuracy: 0.8655 - learning_rate: 0.0010
## Epoch 40/500
## 90/90 - 0s - 2ms/step - loss: 0.2355 - sparse_categorical_accuracy: 0.9014 - val_loss: 0.5160 - val_sparse_categorical_accuracy: 0.7781 - learning_rate: 0.0010
## Epoch 41/500
## 90/90 - 0s - 1ms/step - loss: 0.2139 - sparse_categorical_accuracy: 0.9177 - val_loss: 0.2535 - val_sparse_categorical_accuracy: 0.8988 - learning_rate: 0.0010
## Epoch 42/500
## 90/90 - 0s - 2ms/step - loss: 0.2014 - sparse_categorical_accuracy: 0.9281 - val_loss: 0.5239 - val_sparse_categorical_accuracy: 0.7712 - learning_rate: 0.0010
## Epoch 43/500
## 90/90 - 0s - 1ms/step - loss: 0.2120 - sparse_categorical_accuracy: 0.9177 - val_loss: 0.3141 - val_sparse_categorical_accuracy: 0.8641 - learning_rate: 0.0010
## Epoch 44/500
## 90/90 - 0s - 1ms/step - loss: 0.2068 - sparse_categorical_accuracy: 0.9184 - val_loss: 0.3072 - val_sparse_categorical_accuracy: 0.8766 - learning_rate: 0.0010
## Epoch 45/500
## 90/90 - 0s - 2ms/step - loss: 0.1999 - sparse_categorical_accuracy: 0.9240 - val_loss: 0.2496 - val_sparse_categorical_accuracy: 0.8918 - learning_rate: 0.0010
## Epoch 46/500
## 90/90 - 0s - 2ms/step - loss: 0.2002 - sparse_categorical_accuracy: 0.9236 - val_loss: 0.2228 - val_sparse_categorical_accuracy: 0.8932 - learning_rate: 0.0010
## Epoch 47/500
## 90/90 - 0s - 2ms/step - loss: 0.1839 - sparse_categorical_accuracy: 0.9309 - val_loss: 0.9875 - val_sparse_categorical_accuracy: 0.7087 - learning_rate: 0.0010
## Epoch 48/500
## 90/90 - 0s - 1ms/step - loss: 0.1814 - sparse_categorical_accuracy: 0.9302 - val_loss: 0.3704 - val_sparse_categorical_accuracy: 0.8239 - learning_rate: 0.0010
## Epoch 49/500
## 90/90 - 0s - 2ms/step - loss: 0.1655 - sparse_categorical_accuracy: 0.9389 - val_loss: 0.2146 - val_sparse_categorical_accuracy: 0.9251 - learning_rate: 0.0010
## Epoch 50/500
## 90/90 - 0s - 1ms/step - loss: 0.1681 - sparse_categorical_accuracy: 0.9406 - val_loss: 0.5753 - val_sparse_categorical_accuracy: 0.7129 - learning_rate: 0.0010
## Epoch 51/500
## 90/90 - 0s - 2ms/step - loss: 0.1688 - sparse_categorical_accuracy: 0.9375 - val_loss: 0.1950 - val_sparse_categorical_accuracy: 0.9223 - learning_rate: 0.0010
## Epoch 52/500
## 90/90 - 0s - 2ms/step - loss: 0.1386 - sparse_categorical_accuracy: 0.9514 - val_loss: 0.1877 - val_sparse_categorical_accuracy: 0.9293 - learning_rate: 0.0010
## Epoch 53/500
## 90/90 - 0s - 2ms/step - loss: 0.1313 - sparse_categorical_accuracy: 0.9538 - val_loss: 0.2208 - val_sparse_categorical_accuracy: 0.9154 - learning_rate: 0.0010
## Epoch 54/500
## 90/90 - 0s - 2ms/step - loss: 0.1232 - sparse_categorical_accuracy: 0.9628 - val_loss: 0.1781 - val_sparse_categorical_accuracy: 0.9376 - learning_rate: 0.0010
## Epoch 55/500
## 90/90 - 0s - 2ms/step - loss: 0.1228 - sparse_categorical_accuracy: 0.9580 - val_loss: 0.1534 - val_sparse_categorical_accuracy: 0.9404 - learning_rate: 0.0010
## Epoch 56/500
## 90/90 - 0s - 1ms/step - loss: 0.1237 - sparse_categorical_accuracy: 0.9615 - val_loss: 0.3757 - val_sparse_categorical_accuracy: 0.8488 - learning_rate: 0.0010
## Epoch 57/500
## 90/90 - 0s - 2ms/step - loss: 0.1289 - sparse_categorical_accuracy: 0.9573 - val_loss: 0.1807 - val_sparse_categorical_accuracy: 0.9459 - learning_rate: 0.0010
## Epoch 58/500
## 90/90 - 0s - 1ms/step - loss: 0.1120 - sparse_categorical_accuracy: 0.9625 - val_loss: 0.3541 - val_sparse_categorical_accuracy: 0.8599 - learning_rate: 0.0010
## Epoch 59/500
## 90/90 - 0s - 2ms/step - loss: 0.1234 - sparse_categorical_accuracy: 0.9556 - val_loss: 1.0182 - val_sparse_categorical_accuracy: 0.7184 - learning_rate: 0.0010
## Epoch 60/500
## 90/90 - 0s - 2ms/step - loss: 0.1177 - sparse_categorical_accuracy: 0.9622 - val_loss: 0.1607 - val_sparse_categorical_accuracy: 0.9431 - learning_rate: 0.0010
## Epoch 61/500
## 90/90 - 0s - 2ms/step - loss: 0.1106 - sparse_categorical_accuracy: 0.9667 - val_loss: 0.2572 - val_sparse_categorical_accuracy: 0.9001 - learning_rate: 0.0010
## Epoch 62/500
## 90/90 - 0s - 2ms/step - loss: 0.1247 - sparse_categorical_accuracy: 0.9569 - val_loss: 0.1824 - val_sparse_categorical_accuracy: 0.9404 - learning_rate: 0.0010
## Epoch 63/500
## 90/90 - 0s - 1ms/step - loss: 0.1250 - sparse_categorical_accuracy: 0.9566 - val_loss: 1.9427 - val_sparse_categorical_accuracy: 0.6852 - learning_rate: 0.0010
## Epoch 64/500
## 90/90 - 0s - 2ms/step - loss: 0.1217 - sparse_categorical_accuracy: 0.9580 - val_loss: 0.2182 - val_sparse_categorical_accuracy: 0.8932 - learning_rate: 0.0010
## Epoch 65/500
## 90/90 - 0s - 2ms/step - loss: 0.1164 - sparse_categorical_accuracy: 0.9622 - val_loss: 0.2901 - val_sparse_categorical_accuracy: 0.8863 - learning_rate: 0.0010
## Epoch 66/500
## 90/90 - 0s - 2ms/step - loss: 0.1050 - sparse_categorical_accuracy: 0.9670 - val_loss: 0.1355 - val_sparse_categorical_accuracy: 0.9570 - learning_rate: 0.0010
## Epoch 67/500
## 90/90 - 0s - 2ms/step - loss: 0.1054 - sparse_categorical_accuracy: 0.9656 - val_loss: 0.1319 - val_sparse_categorical_accuracy: 0.9459 - learning_rate: 0.0010
## Epoch 68/500
## 90/90 - 0s - 2ms/step - loss: 0.1076 - sparse_categorical_accuracy: 0.9642 - val_loss: 0.2100 - val_sparse_categorical_accuracy: 0.9126 - learning_rate: 0.0010
## Epoch 69/500
## 90/90 - 0s - 2ms/step - loss: 0.1142 - sparse_categorical_accuracy: 0.9632 - val_loss: 0.7171 - val_sparse_categorical_accuracy: 0.7795 - learning_rate: 0.0010
## Epoch 70/500
## 90/90 - 0s - 1ms/step - loss: 0.1121 - sparse_categorical_accuracy: 0.9618 - val_loss: 0.1473 - val_sparse_categorical_accuracy: 0.9445 - learning_rate: 0.0010
## Epoch 71/500
## 90/90 - 0s - 1ms/step - loss: 0.1109 - sparse_categorical_accuracy: 0.9611 - val_loss: 0.1960 - val_sparse_categorical_accuracy: 0.9196 - learning_rate: 0.0010
## Epoch 72/500
## 90/90 - 0s - 1ms/step - loss: 0.1087 - sparse_categorical_accuracy: 0.9677 - val_loss: 0.7428 - val_sparse_categorical_accuracy: 0.6824 - learning_rate: 0.0010
## Epoch 73/500
## 90/90 - 0s - 1ms/step - loss: 0.1013 - sparse_categorical_accuracy: 0.9705 - val_loss: 0.2467 - val_sparse_categorical_accuracy: 0.8974 - learning_rate: 0.0010
## Epoch 74/500
## 90/90 - 0s - 1ms/step - loss: 0.1031 - sparse_categorical_accuracy: 0.9656 - val_loss: 0.2302 - val_sparse_categorical_accuracy: 0.9154 - learning_rate: 0.0010
## Epoch 75/500
## 90/90 - 0s - 2ms/step - loss: 0.1163 - sparse_categorical_accuracy: 0.9590 - val_loss: 0.4567 - val_sparse_categorical_accuracy: 0.8225 - learning_rate: 0.0010
## Epoch 76/500
## 90/90 - 0s - 1ms/step - loss: 0.1103 - sparse_categorical_accuracy: 0.9635 - val_loss: 0.1538 - val_sparse_categorical_accuracy: 0.9445 - learning_rate: 0.0010
## Epoch 77/500
## 90/90 - 0s - 1ms/step - loss: 0.1015 - sparse_categorical_accuracy: 0.9674 - val_loss: 0.1411 - val_sparse_categorical_accuracy: 0.9417 - learning_rate: 0.0010
## Epoch 78/500
## 90/90 - 0s - 1ms/step - loss: 0.0984 - sparse_categorical_accuracy: 0.9722 - val_loss: 0.1557 - val_sparse_categorical_accuracy: 0.9320 - learning_rate: 0.0010
## Epoch 79/500
## 90/90 - 0s - 1ms/step - loss: 0.1003 - sparse_categorical_accuracy: 0.9653 - val_loss: 0.1712 - val_sparse_categorical_accuracy: 0.9279 - learning_rate: 0.0010
## Epoch 80/500
## 90/90 - 0s - 1ms/step - loss: 0.1011 - sparse_categorical_accuracy: 0.9681 - val_loss: 0.3200 - val_sparse_categorical_accuracy: 0.8641 - learning_rate: 0.0010
## Epoch 81/500
## 90/90 - 0s - 1ms/step - loss: 0.1037 - sparse_categorical_accuracy: 0.9656 - val_loss: 1.1193 - val_sparse_categorical_accuracy: 0.7115 - learning_rate: 0.0010
## Epoch 82/500
## 90/90 - 0s - 1ms/step - loss: 0.0961 - sparse_categorical_accuracy: 0.9677 - val_loss: 0.2175 - val_sparse_categorical_accuracy: 0.9001 - learning_rate: 0.0010
## Epoch 83/500
## 90/90 - 0s - 2ms/step - loss: 0.1022 - sparse_categorical_accuracy: 0.9677 - val_loss: 0.2120 - val_sparse_categorical_accuracy: 0.9043 - learning_rate: 0.0010
## Epoch 84/500
## 90/90 - 0s - 2ms/step - loss: 0.1018 - sparse_categorical_accuracy: 0.9660 - val_loss: 0.1267 - val_sparse_categorical_accuracy: 0.9570 - learning_rate: 0.0010
## Epoch 85/500
## 90/90 - 0s - 2ms/step - loss: 0.0961 - sparse_categorical_accuracy: 0.9698 - val_loss: 0.1361 - val_sparse_categorical_accuracy: 0.9473 - learning_rate: 0.0010
## Epoch 86/500
## 90/90 - 0s - 2ms/step - loss: 0.0941 - sparse_categorical_accuracy: 0.9667 - val_loss: 0.1179 - val_sparse_categorical_accuracy: 0.9528 - learning_rate: 0.0010
## Epoch 87/500
## 90/90 - 0s - 2ms/step - loss: 0.1049 - sparse_categorical_accuracy: 0.9628 - val_loss: 0.3400 - val_sparse_categorical_accuracy: 0.8558 - learning_rate: 0.0010
## Epoch 88/500
## 90/90 - 0s - 2ms/step - loss: 0.1003 - sparse_categorical_accuracy: 0.9646 - val_loss: 0.2261 - val_sparse_categorical_accuracy: 0.9154 - learning_rate: 0.0010
## Epoch 89/500
## 90/90 - 0s - 2ms/step - loss: 0.1001 - sparse_categorical_accuracy: 0.9649 - val_loss: 0.1882 - val_sparse_categorical_accuracy: 0.9307 - learning_rate: 0.0010
## Epoch 90/500
## 90/90 - 0s - 1ms/step - loss: 0.0983 - sparse_categorical_accuracy: 0.9663 - val_loss: 0.2872 - val_sparse_categorical_accuracy: 0.8849 - learning_rate: 0.0010
## Epoch 91/500
## 90/90 - 0s - 1ms/step - loss: 0.0993 - sparse_categorical_accuracy: 0.9670 - val_loss: 0.6993 - val_sparse_categorical_accuracy: 0.7101 - learning_rate: 0.0010
## Epoch 92/500
## 90/90 - 0s - 1ms/step - loss: 0.0948 - sparse_categorical_accuracy: 0.9691 - val_loss: 0.1244 - val_sparse_categorical_accuracy: 0.9528 - learning_rate: 0.0010
## Epoch 93/500
## 90/90 - 0s - 1ms/step - loss: 0.0955 - sparse_categorical_accuracy: 0.9691 - val_loss: 0.1323 - val_sparse_categorical_accuracy: 0.9431 - learning_rate: 0.0010
## Epoch 94/500
## 90/90 - 0s - 1ms/step - loss: 0.0984 - sparse_categorical_accuracy: 0.9670 - val_loss: 0.3915 - val_sparse_categorical_accuracy: 0.8627 - learning_rate: 0.0010
## Epoch 95/500
## 90/90 - 0s - 2ms/step - loss: 0.0969 - sparse_categorical_accuracy: 0.9642 - val_loss: 0.1148 - val_sparse_categorical_accuracy: 0.9556 - learning_rate: 0.0010
## Epoch 96/500
## 90/90 - 0s - 1ms/step - loss: 0.1038 - sparse_categorical_accuracy: 0.9597 - val_loss: 1.7709 - val_sparse_categorical_accuracy: 0.6644 - learning_rate: 0.0010
## Epoch 97/500
## 90/90 - 0s - 1ms/step - loss: 0.1095 - sparse_categorical_accuracy: 0.9618 - val_loss: 0.1269 - val_sparse_categorical_accuracy: 0.9501 - learning_rate: 0.0010
## Epoch 98/500
## 90/90 - 0s - 2ms/step - loss: 0.0920 - sparse_categorical_accuracy: 0.9698 - val_loss: 0.1242 - val_sparse_categorical_accuracy: 0.9501 - learning_rate: 0.0010
## Epoch 99/500
## 90/90 - 0s - 2ms/step - loss: 0.0982 - sparse_categorical_accuracy: 0.9635 - val_loss: 1.5810 - val_sparse_categorical_accuracy: 0.7323 - learning_rate: 0.0010
## Epoch 100/500
## 90/90 - 0s - 1ms/step - loss: 0.0888 - sparse_categorical_accuracy: 0.9729 - val_loss: 1.0193 - val_sparse_categorical_accuracy: 0.7184 - learning_rate: 0.0010
## Epoch 101/500
## 90/90 - 0s - 1ms/step - loss: 0.0880 - sparse_categorical_accuracy: 0.9705 - val_loss: 0.3746 - val_sparse_categorical_accuracy: 0.8460 - learning_rate: 0.0010
## Epoch 102/500
## 90/90 - 0s - 2ms/step - loss: 0.0940 - sparse_categorical_accuracy: 0.9715 - val_loss: 0.4822 - val_sparse_categorical_accuracy: 0.7975 - learning_rate: 0.0010
## Epoch 103/500
## 90/90 - 0s - 2ms/step - loss: 0.0913 - sparse_categorical_accuracy: 0.9740 - val_loss: 0.3391 - val_sparse_categorical_accuracy: 0.8682 - learning_rate: 0.0010
## Epoch 104/500
## 90/90 - 0s - 1ms/step - loss: 0.0950 - sparse_categorical_accuracy: 0.9674 - val_loss: 1.3815 - val_sparse_categorical_accuracy: 0.5950 - learning_rate: 0.0010
## Epoch 105/500
## 90/90 - 0s - 1ms/step - loss: 0.0937 - sparse_categorical_accuracy: 0.9698 - val_loss: 0.1849 - val_sparse_categorical_accuracy: 0.9265 - learning_rate: 0.0010
## Epoch 106/500
## 90/90 - 0s - 1ms/step - loss: 0.0920 - sparse_categorical_accuracy: 0.9677 - val_loss: 0.1472 - val_sparse_categorical_accuracy: 0.9528 - learning_rate: 0.0010
## Epoch 107/500
## 90/90 - 0s - 1ms/step - loss: 0.0913 - sparse_categorical_accuracy: 0.9705 - val_loss: 0.2803 - val_sparse_categorical_accuracy: 0.8904 - learning_rate: 0.0010
## Epoch 108/500
## 90/90 - 0s - 2ms/step - loss: 0.0856 - sparse_categorical_accuracy: 0.9705 - val_loss: 0.1140 - val_sparse_categorical_accuracy: 0.9556 - learning_rate: 0.0010
## Epoch 109/500
## 90/90 - 0s - 2ms/step - loss: 0.0936 - sparse_categorical_accuracy: 0.9708 - val_loss: 0.1559 - val_sparse_categorical_accuracy: 0.9431 - learning_rate: 0.0010
## Epoch 110/500
## 90/90 - 0s - 1ms/step - loss: 0.0975 - sparse_categorical_accuracy: 0.9688 - val_loss: 0.1234 - val_sparse_categorical_accuracy: 0.9556 - learning_rate: 0.0010
## Epoch 111/500
## 90/90 - 0s - 2ms/step - loss: 0.0838 - sparse_categorical_accuracy: 0.9729 - val_loss: 0.1509 - val_sparse_categorical_accuracy: 0.9404 - learning_rate: 0.0010
## Epoch 112/500
## 90/90 - 0s - 2ms/step - loss: 0.0847 - sparse_categorical_accuracy: 0.9708 - val_loss: 0.4432 - val_sparse_categorical_accuracy: 0.8419 - learning_rate: 0.0010
## Epoch 113/500
## 90/90 - 0s - 1ms/step - loss: 0.0861 - sparse_categorical_accuracy: 0.9712 - val_loss: 0.9690 - val_sparse_categorical_accuracy: 0.7573 - learning_rate: 0.0010
## Epoch 114/500
## 90/90 - 0s - 1ms/step - loss: 0.1003 - sparse_categorical_accuracy: 0.9656 - val_loss: 3.2381 - val_sparse_categorical_accuracy: 0.6241 - learning_rate: 0.0010
## Epoch 115/500
## 90/90 - 0s - 2ms/step - loss: 0.0863 - sparse_categorical_accuracy: 0.9670 - val_loss: 2.0907 - val_sparse_categorical_accuracy: 0.6519 - learning_rate: 0.0010
## Epoch 116/500
## 90/90 - 0s - 2ms/step - loss: 0.0865 - sparse_categorical_accuracy: 0.9743 - val_loss: 1.0374 - val_sparse_categorical_accuracy: 0.7143 - learning_rate: 0.0010
## Epoch 117/500
## 90/90 - 0s - 2ms/step - loss: 0.0778 - sparse_categorical_accuracy: 0.9740 - val_loss: 0.1358 - val_sparse_categorical_accuracy: 0.9431 - learning_rate: 0.0010
## Epoch 118/500
## 90/90 - 0s - 2ms/step - loss: 0.0873 - sparse_categorical_accuracy: 0.9712 - val_loss: 0.3265 - val_sparse_categorical_accuracy: 0.8682 - learning_rate: 0.0010
## Epoch 119/500
## 90/90 - 0s - 2ms/step - loss: 0.0924 - sparse_categorical_accuracy: 0.9667 - val_loss: 0.1080 - val_sparse_categorical_accuracy: 0.9528 - learning_rate: 0.0010
## Epoch 120/500
## 90/90 - 0s - 2ms/step - loss: 0.0866 - sparse_categorical_accuracy: 0.9729 - val_loss: 0.1150 - val_sparse_categorical_accuracy: 0.9528 - learning_rate: 0.0010
## Epoch 121/500
## 90/90 - 0s - 2ms/step - loss: 0.0872 - sparse_categorical_accuracy: 0.9712 - val_loss: 0.4243 - val_sparse_categorical_accuracy: 0.8599 - learning_rate: 0.0010
## Epoch 122/500
## 90/90 - 0s - 1ms/step - loss: 0.0881 - sparse_categorical_accuracy: 0.9681 - val_loss: 0.1352 - val_sparse_categorical_accuracy: 0.9556 - learning_rate: 0.0010
## Epoch 123/500
## 90/90 - 0s - 1ms/step - loss: 0.0872 - sparse_categorical_accuracy: 0.9701 - val_loss: 0.1809 - val_sparse_categorical_accuracy: 0.9265 - learning_rate: 0.0010
## Epoch 124/500
## 90/90 - 0s - 2ms/step - loss: 0.0905 - sparse_categorical_accuracy: 0.9670 - val_loss: 0.3625 - val_sparse_categorical_accuracy: 0.8669 - learning_rate: 0.0010
## Epoch 125/500
## 90/90 - 0s - 1ms/step - loss: 0.0866 - sparse_categorical_accuracy: 0.9701 - val_loss: 0.1339 - val_sparse_categorical_accuracy: 0.9445 - learning_rate: 0.0010
## Epoch 126/500
## 90/90 - 0s - 1ms/step - loss: 0.0821 - sparse_categorical_accuracy: 0.9733 - val_loss: 0.2196 - val_sparse_categorical_accuracy: 0.9098 - learning_rate: 0.0010
## Epoch 127/500
## 90/90 - 0s - 1ms/step - loss: 0.0849 - sparse_categorical_accuracy: 0.9733 - val_loss: 0.1554 - val_sparse_categorical_accuracy: 0.9417 - learning_rate: 0.0010
## Epoch 128/500
## 90/90 - 0s - 1ms/step - loss: 0.0869 - sparse_categorical_accuracy: 0.9691 - val_loss: 0.1836 - val_sparse_categorical_accuracy: 0.9307 - learning_rate: 0.0010
## Epoch 129/500
## 90/90 - 0s - 1ms/step - loss: 0.0872 - sparse_categorical_accuracy: 0.9715 - val_loss: 0.1344 - val_sparse_categorical_accuracy: 0.9487 - learning_rate: 0.0010
## Epoch 130/500
## 90/90 - 0s - 1ms/step - loss: 0.0993 - sparse_categorical_accuracy: 0.9653 - val_loss: 0.2933 - val_sparse_categorical_accuracy: 0.8793 - learning_rate: 0.0010
## Epoch 131/500
## 90/90 - 0s - 1ms/step - loss: 0.0789 - sparse_categorical_accuracy: 0.9750 - val_loss: 0.2245 - val_sparse_categorical_accuracy: 0.9015 - learning_rate: 0.0010
## Epoch 132/500
## 90/90 - 0s - 1ms/step - loss: 0.0752 - sparse_categorical_accuracy: 0.9753 - val_loss: 0.1335 - val_sparse_categorical_accuracy: 0.9515 - learning_rate: 0.0010
## Epoch 133/500
## 90/90 - 0s - 1ms/step - loss: 0.0725 - sparse_categorical_accuracy: 0.9767 - val_loss: 0.3275 - val_sparse_categorical_accuracy: 0.8849 - learning_rate: 0.0010
## Epoch 134/500
## 90/90 - 0s - 2ms/step - loss: 0.0838 - sparse_categorical_accuracy: 0.9736 - val_loss: 0.1100 - val_sparse_categorical_accuracy: 0.9556 - learning_rate: 0.0010
## Epoch 135/500
## 90/90 - 0s - 1ms/step - loss: 0.0806 - sparse_categorical_accuracy: 0.9743 - val_loss: 0.1631 - val_sparse_categorical_accuracy: 0.9431 - learning_rate: 0.0010
## Epoch 136/500
## 90/90 - 0s - 1ms/step - loss: 0.0868 - sparse_categorical_accuracy: 0.9684 - val_loss: 0.2202 - val_sparse_categorical_accuracy: 0.9126 - learning_rate: 0.0010
## Epoch 137/500
## 90/90 - 0s - 1ms/step - loss: 0.0955 - sparse_categorical_accuracy: 0.9701 - val_loss: 0.1584 - val_sparse_categorical_accuracy: 0.9417 - learning_rate: 0.0010
## Epoch 138/500
## 90/90 - 0s - 1ms/step - loss: 0.0853 - sparse_categorical_accuracy: 0.9729 - val_loss: 0.1254 - val_sparse_categorical_accuracy: 0.9501 - learning_rate: 0.0010
## Epoch 139/500
## 90/90 - 0s - 2ms/step - loss: 0.0911 - sparse_categorical_accuracy: 0.9698 - val_loss: 0.1068 - val_sparse_categorical_accuracy: 0.9598 - learning_rate: 0.0010
## Epoch 140/500
## 90/90 - 0s - 2ms/step - loss: 0.0763 - sparse_categorical_accuracy: 0.9750 - val_loss: 0.1395 - val_sparse_categorical_accuracy: 0.9487 - learning_rate: 0.0010
## Epoch 141/500
## 90/90 - 0s - 2ms/step - loss: 0.0827 - sparse_categorical_accuracy: 0.9705 - val_loss: 0.4026 - val_sparse_categorical_accuracy: 0.8391 - learning_rate: 0.0010
## Epoch 142/500
## 90/90 - 0s - 2ms/step - loss: 0.0752 - sparse_categorical_accuracy: 0.9767 - val_loss: 0.3826 - val_sparse_categorical_accuracy: 0.8405 - learning_rate: 0.0010
## Epoch 143/500
## 90/90 - 0s - 1ms/step - loss: 0.0826 - sparse_categorical_accuracy: 0.9708 - val_loss: 0.1629 - val_sparse_categorical_accuracy: 0.9362 - learning_rate: 0.0010
## Epoch 144/500
## 90/90 - 0s - 1ms/step - loss: 0.0780 - sparse_categorical_accuracy: 0.9757 - val_loss: 0.1141 - val_sparse_categorical_accuracy: 0.9556 - learning_rate: 0.0010
## Epoch 145/500
## 90/90 - 0s - 1ms/step - loss: 0.0768 - sparse_categorical_accuracy: 0.9740 - val_loss: 0.6703 - val_sparse_categorical_accuracy: 0.8086 - learning_rate: 0.0010
## Epoch 146/500
## 90/90 - 0s - 1ms/step - loss: 0.0809 - sparse_categorical_accuracy: 0.9736 - val_loss: 0.1486 - val_sparse_categorical_accuracy: 0.9459 - learning_rate: 0.0010
## Epoch 147/500
## 90/90 - 0s - 2ms/step - loss: 0.0875 - sparse_categorical_accuracy: 0.9681 - val_loss: 0.1058 - val_sparse_categorical_accuracy: 0.9639 - learning_rate: 0.0010
## Epoch 148/500
## 90/90 - 0s - 2ms/step - loss: 0.0930 - sparse_categorical_accuracy: 0.9688 - val_loss: 0.2399 - val_sparse_categorical_accuracy: 0.9029 - learning_rate: 0.0010
## Epoch 149/500
## 90/90 - 0s - 2ms/step - loss: 0.0806 - sparse_categorical_accuracy: 0.9708 - val_loss: 0.1085 - val_sparse_categorical_accuracy: 0.9528 - learning_rate: 0.0010
## Epoch 150/500
## 90/90 - 0s - 1ms/step - loss: 0.0790 - sparse_categorical_accuracy: 0.9736 - val_loss: 0.1384 - val_sparse_categorical_accuracy: 0.9473 - learning_rate: 0.0010
## Epoch 151/500
## 90/90 - 0s - 1ms/step - loss: 0.0744 - sparse_categorical_accuracy: 0.9764 - val_loss: 0.5306 - val_sparse_categorical_accuracy: 0.8086 - learning_rate: 0.0010
## Epoch 152/500
## 90/90 - 0s - 1ms/step - loss: 0.0784 - sparse_categorical_accuracy: 0.9722 - val_loss: 0.1270 - val_sparse_categorical_accuracy: 0.9598 - learning_rate: 0.0010
## Epoch 153/500
## 90/90 - 0s - 1ms/step - loss: 0.0764 - sparse_categorical_accuracy: 0.9743 - val_loss: 0.5285 - val_sparse_categorical_accuracy: 0.8155 - learning_rate: 0.0010
## Epoch 154/500
## 90/90 - 0s - 2ms/step - loss: 0.0785 - sparse_categorical_accuracy: 0.9722 - val_loss: 0.3310 - val_sparse_categorical_accuracy: 0.8932 - learning_rate: 0.0010
## Epoch 155/500
## 90/90 - 0s - 2ms/step - loss: 0.0749 - sparse_categorical_accuracy: 0.9740 - val_loss: 0.1137 - val_sparse_categorical_accuracy: 0.9556 - learning_rate: 0.0010
## Epoch 156/500
## 90/90 - 0s - 2ms/step - loss: 0.0813 - sparse_categorical_accuracy: 0.9729 - val_loss: 0.1311 - val_sparse_categorical_accuracy: 0.9473 - learning_rate: 0.0010
## Epoch 157/500
## 90/90 - 0s - 2ms/step - loss: 0.0790 - sparse_categorical_accuracy: 0.9698 - val_loss: 0.1033 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 0.0010
## Epoch 158/500
## 90/90 - 0s - 1ms/step - loss: 0.0784 - sparse_categorical_accuracy: 0.9726 - val_loss: 0.1289 - val_sparse_categorical_accuracy: 0.9417 - learning_rate: 0.0010
## Epoch 159/500
## 90/90 - 0s - 2ms/step - loss: 0.0771 - sparse_categorical_accuracy: 0.9726 - val_loss: 0.6226 - val_sparse_categorical_accuracy: 0.7850 - learning_rate: 0.0010
## Epoch 160/500
## 90/90 - 0s - 2ms/step - loss: 0.0805 - sparse_categorical_accuracy: 0.9694 - val_loss: 0.1197 - val_sparse_categorical_accuracy: 0.9598 - learning_rate: 0.0010
## Epoch 161/500
## 90/90 - 0s - 2ms/step - loss: 0.0741 - sparse_categorical_accuracy: 0.9753 - val_loss: 0.4097 - val_sparse_categorical_accuracy: 0.8613 - learning_rate: 0.0010
## Epoch 162/500
## 90/90 - 0s - 2ms/step - loss: 0.0729 - sparse_categorical_accuracy: 0.9764 - val_loss: 0.2100 - val_sparse_categorical_accuracy: 0.9098 - learning_rate: 0.0010
## Epoch 163/500
## 90/90 - 0s - 1ms/step - loss: 0.0700 - sparse_categorical_accuracy: 0.9760 - val_loss: 0.1946 - val_sparse_categorical_accuracy: 0.9362 - learning_rate: 0.0010
## Epoch 164/500
## 90/90 - 0s - 2ms/step - loss: 0.0695 - sparse_categorical_accuracy: 0.9757 - val_loss: 0.1297 - val_sparse_categorical_accuracy: 0.9626 - learning_rate: 0.0010
## Epoch 165/500
## 90/90 - 0s - 2ms/step - loss: 0.0743 - sparse_categorical_accuracy: 0.9698 - val_loss: 0.2311 - val_sparse_categorical_accuracy: 0.9085 - learning_rate: 0.0010
## Epoch 166/500
## 90/90 - 0s - 2ms/step - loss: 0.0703 - sparse_categorical_accuracy: 0.9760 - val_loss: 0.4873 - val_sparse_categorical_accuracy: 0.8433 - learning_rate: 0.0010
## Epoch 167/500
## 90/90 - 0s - 2ms/step - loss: 0.0713 - sparse_categorical_accuracy: 0.9771 - val_loss: 0.2705 - val_sparse_categorical_accuracy: 0.9154 - learning_rate: 0.0010
## Epoch 168/500
## 90/90 - 0s - 2ms/step - loss: 0.0842 - sparse_categorical_accuracy: 0.9684 - val_loss: 0.2207 - val_sparse_categorical_accuracy: 0.9251 - learning_rate: 0.0010
## Epoch 169/500
## 90/90 - 0s - 1ms/step - loss: 0.0748 - sparse_categorical_accuracy: 0.9747 - val_loss: 0.1088 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 0.0010
## Epoch 170/500
## 90/90 - 0s - 1ms/step - loss: 0.0728 - sparse_categorical_accuracy: 0.9764 - val_loss: 0.2704 - val_sparse_categorical_accuracy: 0.9071 - learning_rate: 0.0010
## Epoch 171/500
## 90/90 - 0s - 1ms/step - loss: 0.0653 - sparse_categorical_accuracy: 0.9764 - val_loss: 0.1132 - val_sparse_categorical_accuracy: 0.9639 - learning_rate: 0.0010
## Epoch 172/500
## 90/90 - 0s - 2ms/step - loss: 0.0722 - sparse_categorical_accuracy: 0.9729 - val_loss: 0.0939 - val_sparse_categorical_accuracy: 0.9639 - learning_rate: 0.0010
## Epoch 173/500
## 90/90 - 0s - 2ms/step - loss: 0.0685 - sparse_categorical_accuracy: 0.9774 - val_loss: 1.7697 - val_sparse_categorical_accuracy: 0.7115 - learning_rate: 0.0010
## Epoch 174/500
## 90/90 - 0s - 2ms/step - loss: 0.0715 - sparse_categorical_accuracy: 0.9774 - val_loss: 0.1295 - val_sparse_categorical_accuracy: 0.9528 - learning_rate: 0.0010
## Epoch 175/500
## 90/90 - 0s - 2ms/step - loss: 0.0792 - sparse_categorical_accuracy: 0.9726 - val_loss: 0.1472 - val_sparse_categorical_accuracy: 0.9417 - learning_rate: 0.0010
## Epoch 176/500
## 90/90 - 0s - 1ms/step - loss: 0.0746 - sparse_categorical_accuracy: 0.9753 - val_loss: 0.0997 - val_sparse_categorical_accuracy: 0.9667 - learning_rate: 0.0010
## Epoch 177/500
## 90/90 - 0s - 2ms/step - loss: 0.0736 - sparse_categorical_accuracy: 0.9753 - val_loss: 0.1024 - val_sparse_categorical_accuracy: 0.9556 - learning_rate: 0.0010
## Epoch 178/500
## 90/90 - 0s - 2ms/step - loss: 0.0657 - sparse_categorical_accuracy: 0.9785 - val_loss: 0.1353 - val_sparse_categorical_accuracy: 0.9501 - learning_rate: 0.0010
## Epoch 179/500
## 90/90 - 0s - 2ms/step - loss: 0.0660 - sparse_categorical_accuracy: 0.9764 - val_loss: 0.2035 - val_sparse_categorical_accuracy: 0.9237 - learning_rate: 0.0010
## Epoch 180/500
## 90/90 - 0s - 2ms/step - loss: 0.0715 - sparse_categorical_accuracy: 0.9750 - val_loss: 0.2970 - val_sparse_categorical_accuracy: 0.9029 - learning_rate: 0.0010
## Epoch 181/500
## 90/90 - 0s - 1ms/step - loss: 0.0736 - sparse_categorical_accuracy: 0.9760 - val_loss: 1.2027 - val_sparse_categorical_accuracy: 0.7087 - learning_rate: 0.0010
## Epoch 182/500
## 90/90 - 0s - 1ms/step - loss: 0.0668 - sparse_categorical_accuracy: 0.9819 - val_loss: 0.1218 - val_sparse_categorical_accuracy: 0.9570 - learning_rate: 0.0010
## Epoch 183/500
## 90/90 - 0s - 1ms/step - loss: 0.0724 - sparse_categorical_accuracy: 0.9750 - val_loss: 0.1155 - val_sparse_categorical_accuracy: 0.9626 - learning_rate: 0.0010
## Epoch 184/500
## 90/90 - 0s - 1ms/step - loss: 0.0673 - sparse_categorical_accuracy: 0.9778 - val_loss: 0.1015 - val_sparse_categorical_accuracy: 0.9626 - learning_rate: 0.0010
## Epoch 185/500
## 90/90 - 0s - 1ms/step - loss: 0.0633 - sparse_categorical_accuracy: 0.9774 - val_loss: 0.7518 - val_sparse_categorical_accuracy: 0.7295 - learning_rate: 0.0010
## Epoch 186/500
## 90/90 - 0s - 1ms/step - loss: 0.0878 - sparse_categorical_accuracy: 0.9722 - val_loss: 1.2166 - val_sparse_categorical_accuracy: 0.7087 - learning_rate: 0.0010
## Epoch 187/500
## 90/90 - 0s - 1ms/step - loss: 0.0667 - sparse_categorical_accuracy: 0.9757 - val_loss: 0.3105 - val_sparse_categorical_accuracy: 0.8710 - learning_rate: 0.0010
## Epoch 188/500
## 90/90 - 0s - 1ms/step - loss: 0.0636 - sparse_categorical_accuracy: 0.9778 - val_loss: 0.1036 - val_sparse_categorical_accuracy: 0.9667 - learning_rate: 0.0010
## Epoch 189/500
## 90/90 - 0s - 1ms/step - loss: 0.0607 - sparse_categorical_accuracy: 0.9795 - val_loss: 0.1040 - val_sparse_categorical_accuracy: 0.9695 - learning_rate: 0.0010
## Epoch 190/500
## 90/90 - 0s - 1ms/step - loss: 0.0698 - sparse_categorical_accuracy: 0.9771 - val_loss: 0.2649 - val_sparse_categorical_accuracy: 0.8988 - learning_rate: 0.0010
## Epoch 191/500
## 90/90 - 0s - 1ms/step - loss: 0.0678 - sparse_categorical_accuracy: 0.9719 - val_loss: 0.1108 - val_sparse_categorical_accuracy: 0.9639 - learning_rate: 0.0010
## Epoch 192/500
## 90/90 - 0s - 1ms/step - loss: 0.0762 - sparse_categorical_accuracy: 0.9740 - val_loss: 0.2119 - val_sparse_categorical_accuracy: 0.9223 - learning_rate: 0.0010
## Epoch 193/500
## 90/90 - 0s - 2ms/step - loss: 0.0591 - sparse_categorical_accuracy: 0.9802 - val_loss: 0.0995 - val_sparse_categorical_accuracy: 0.9639 - learning_rate: 5.0000e-04
## Epoch 194/500
## 90/90 - 0s - 2ms/step - loss: 0.0557 - sparse_categorical_accuracy: 0.9788 - val_loss: 0.2538 - val_sparse_categorical_accuracy: 0.8946 - learning_rate: 5.0000e-04
## Epoch 195/500
## 90/90 - 0s - 2ms/step - loss: 0.0542 - sparse_categorical_accuracy: 0.9830 - val_loss: 0.0923 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 5.0000e-04
## Epoch 196/500
## 90/90 - 0s - 2ms/step - loss: 0.0597 - sparse_categorical_accuracy: 0.9785 - val_loss: 0.1308 - val_sparse_categorical_accuracy: 0.9417 - learning_rate: 5.0000e-04
## Epoch 197/500
## 90/90 - 0s - 2ms/step - loss: 0.0581 - sparse_categorical_accuracy: 0.9806 - val_loss: 0.1103 - val_sparse_categorical_accuracy: 0.9445 - learning_rate: 5.0000e-04
## Epoch 198/500
## 90/90 - 0s - 2ms/step - loss: 0.0558 - sparse_categorical_accuracy: 0.9840 - val_loss: 0.0968 - val_sparse_categorical_accuracy: 0.9598 - learning_rate: 5.0000e-04
## Epoch 199/500
## 90/90 - 0s - 2ms/step - loss: 0.0586 - sparse_categorical_accuracy: 0.9826 - val_loss: 0.0968 - val_sparse_categorical_accuracy: 0.9598 - learning_rate: 5.0000e-04
## Epoch 200/500
## 90/90 - 0s - 2ms/step - loss: 0.0588 - sparse_categorical_accuracy: 0.9802 - val_loss: 0.1007 - val_sparse_categorical_accuracy: 0.9667 - learning_rate: 5.0000e-04
## Epoch 201/500
## 90/90 - 0s - 2ms/step - loss: 0.0542 - sparse_categorical_accuracy: 0.9844 - val_loss: 0.1308 - val_sparse_categorical_accuracy: 0.9584 - learning_rate: 5.0000e-04
## Epoch 202/500
## 90/90 - 0s - 2ms/step - loss: 0.0541 - sparse_categorical_accuracy: 0.9809 - val_loss: 0.1637 - val_sparse_categorical_accuracy: 0.9293 - learning_rate: 5.0000e-04
## Epoch 203/500
## 90/90 - 0s - 2ms/step - loss: 0.0537 - sparse_categorical_accuracy: 0.9833 - val_loss: 0.1446 - val_sparse_categorical_accuracy: 0.9362 - learning_rate: 5.0000e-04
## Epoch 204/500
## 90/90 - 0s - 2ms/step - loss: 0.0505 - sparse_categorical_accuracy: 0.9837 - val_loss: 0.0862 - val_sparse_categorical_accuracy: 0.9667 - learning_rate: 5.0000e-04
## Epoch 205/500
## 90/90 - 0s - 2ms/step - loss: 0.0522 - sparse_categorical_accuracy: 0.9833 - val_loss: 0.1284 - val_sparse_categorical_accuracy: 0.9584 - learning_rate: 5.0000e-04
## Epoch 206/500
## 90/90 - 0s - 2ms/step - loss: 0.0564 - sparse_categorical_accuracy: 0.9816 - val_loss: 0.2165 - val_sparse_categorical_accuracy: 0.9279 - learning_rate: 5.0000e-04
## Epoch 207/500
## 90/90 - 0s - 2ms/step - loss: 0.0602 - sparse_categorical_accuracy: 0.9774 - val_loss: 0.1575 - val_sparse_categorical_accuracy: 0.9459 - learning_rate: 5.0000e-04
## Epoch 208/500
## 90/90 - 0s - 2ms/step - loss: 0.0536 - sparse_categorical_accuracy: 0.9813 - val_loss: 0.1823 - val_sparse_categorical_accuracy: 0.9362 - learning_rate: 5.0000e-04
## Epoch 209/500
## 90/90 - 0s - 2ms/step - loss: 0.0513 - sparse_categorical_accuracy: 0.9799 - val_loss: 0.1069 - val_sparse_categorical_accuracy: 0.9695 - learning_rate: 5.0000e-04
## Epoch 210/500
## 90/90 - 0s - 1ms/step - loss: 0.0564 - sparse_categorical_accuracy: 0.9809 - val_loss: 0.0963 - val_sparse_categorical_accuracy: 0.9612 - learning_rate: 5.0000e-04
## Epoch 211/500
## 90/90 - 0s - 1ms/step - loss: 0.0517 - sparse_categorical_accuracy: 0.9833 - val_loss: 0.1517 - val_sparse_categorical_accuracy: 0.9390 - learning_rate: 5.0000e-04
## Epoch 212/500
## 90/90 - 0s - 2ms/step - loss: 0.0526 - sparse_categorical_accuracy: 0.9844 - val_loss: 0.1380 - val_sparse_categorical_accuracy: 0.9390 - learning_rate: 5.0000e-04
## Epoch 213/500
## 90/90 - 0s - 1ms/step - loss: 0.0542 - sparse_categorical_accuracy: 0.9840 - val_loss: 0.1223 - val_sparse_categorical_accuracy: 0.9598 - learning_rate: 5.0000e-04
## Epoch 214/500
## 90/90 - 0s - 1ms/step - loss: 0.0531 - sparse_categorical_accuracy: 0.9830 - val_loss: 0.0920 - val_sparse_categorical_accuracy: 0.9598 - learning_rate: 5.0000e-04
## Epoch 215/500
## 90/90 - 0s - 1ms/step - loss: 0.0487 - sparse_categorical_accuracy: 0.9858 - val_loss: 0.1777 - val_sparse_categorical_accuracy: 0.9251 - learning_rate: 5.0000e-04
## Epoch 216/500
## 90/90 - 0s - 1ms/step - loss: 0.0506 - sparse_categorical_accuracy: 0.9837 - val_loss: 0.1178 - val_sparse_categorical_accuracy: 0.9681 - learning_rate: 5.0000e-04
## Epoch 217/500
## 90/90 - 0s - 1ms/step - loss: 0.0517 - sparse_categorical_accuracy: 0.9844 - val_loss: 0.1044 - val_sparse_categorical_accuracy: 0.9709 - learning_rate: 5.0000e-04
## Epoch 218/500
## 90/90 - 0s - 2ms/step - loss: 0.0569 - sparse_categorical_accuracy: 0.9816 - val_loss: 0.1292 - val_sparse_categorical_accuracy: 0.9570 - learning_rate: 5.0000e-04
## Epoch 219/500
## 90/90 - 0s - 1ms/step - loss: 0.0548 - sparse_categorical_accuracy: 0.9802 - val_loss: 0.0950 - val_sparse_categorical_accuracy: 0.9723 - learning_rate: 5.0000e-04
## Epoch 220/500
## 90/90 - 0s - 1ms/step - loss: 0.0513 - sparse_categorical_accuracy: 0.9840 - val_loss: 0.1101 - val_sparse_categorical_accuracy: 0.9681 - learning_rate: 5.0000e-04
## Epoch 221/500
## 90/90 - 0s - 1ms/step - loss: 0.0507 - sparse_categorical_accuracy: 0.9813 - val_loss: 0.1649 - val_sparse_categorical_accuracy: 0.9279 - learning_rate: 5.0000e-04
## Epoch 222/500
## 90/90 - 0s - 1ms/step - loss: 0.0526 - sparse_categorical_accuracy: 0.9816 - val_loss: 0.0896 - val_sparse_categorical_accuracy: 0.9667 - learning_rate: 5.0000e-04
## Epoch 223/500
## 90/90 - 0s - 2ms/step - loss: 0.0477 - sparse_categorical_accuracy: 0.9830 - val_loss: 0.1106 - val_sparse_categorical_accuracy: 0.9626 - learning_rate: 5.0000e-04
## Epoch 224/500
## 90/90 - 0s - 1ms/step - loss: 0.0469 - sparse_categorical_accuracy: 0.9858 - val_loss: 0.1441 - val_sparse_categorical_accuracy: 0.9431 - learning_rate: 5.0000e-04
## Epoch 225/500
## 90/90 - 0s - 1ms/step - loss: 0.0470 - sparse_categorical_accuracy: 0.9865 - val_loss: 0.0928 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 2.5000e-04
## Epoch 226/500
## 90/90 - 0s - 1ms/step - loss: 0.0422 - sparse_categorical_accuracy: 0.9861 - val_loss: 0.0930 - val_sparse_categorical_accuracy: 0.9750 - learning_rate: 2.5000e-04
## Epoch 227/500
## 90/90 - 0s - 1ms/step - loss: 0.0465 - sparse_categorical_accuracy: 0.9847 - val_loss: 0.0999 - val_sparse_categorical_accuracy: 0.9584 - learning_rate: 2.5000e-04
## Epoch 228/500
## 90/90 - 0s - 1ms/step - loss: 0.0411 - sparse_categorical_accuracy: 0.9910 - val_loss: 0.0927 - val_sparse_categorical_accuracy: 0.9612 - learning_rate: 2.5000e-04
## Epoch 229/500
## 90/90 - 0s - 1ms/step - loss: 0.0436 - sparse_categorical_accuracy: 0.9868 - val_loss: 0.0896 - val_sparse_categorical_accuracy: 0.9626 - learning_rate: 2.5000e-04
## Epoch 230/500
## 90/90 - 0s - 2ms/step - loss: 0.0408 - sparse_categorical_accuracy: 0.9868 - val_loss: 0.1114 - val_sparse_categorical_accuracy: 0.9556 - learning_rate: 2.5000e-04
## Epoch 231/500
## 90/90 - 0s - 2ms/step - loss: 0.0445 - sparse_categorical_accuracy: 0.9868 - val_loss: 0.0999 - val_sparse_categorical_accuracy: 0.9639 - learning_rate: 2.5000e-04
## Epoch 232/500
## 90/90 - 0s - 2ms/step - loss: 0.0418 - sparse_categorical_accuracy: 0.9885 - val_loss: 0.1339 - val_sparse_categorical_accuracy: 0.9556 - learning_rate: 2.5000e-04
## Epoch 233/500
## 90/90 - 0s - 1ms/step - loss: 0.0423 - sparse_categorical_accuracy: 0.9872 - val_loss: 0.0898 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 2.5000e-04
## Epoch 234/500
## 90/90 - 0s - 1ms/step - loss: 0.0443 - sparse_categorical_accuracy: 0.9868 - val_loss: 0.1366 - val_sparse_categorical_accuracy: 0.9556 - learning_rate: 2.5000e-04
## Epoch 235/500
## 90/90 - 0s - 2ms/step - loss: 0.0443 - sparse_categorical_accuracy: 0.9844 - val_loss: 0.0889 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 2.5000e-04
## Epoch 236/500
## 90/90 - 0s - 2ms/step - loss: 0.0465 - sparse_categorical_accuracy: 0.9826 - val_loss: 0.0967 - val_sparse_categorical_accuracy: 0.9626 - learning_rate: 2.5000e-04
## Epoch 237/500
## 90/90 - 0s - 1ms/step - loss: 0.0443 - sparse_categorical_accuracy: 0.9851 - val_loss: 0.1487 - val_sparse_categorical_accuracy: 0.9528 - learning_rate: 2.5000e-04
## Epoch 238/500
## 90/90 - 0s - 1ms/step - loss: 0.0418 - sparse_categorical_accuracy: 0.9872 - val_loss: 0.0899 - val_sparse_categorical_accuracy: 0.9681 - learning_rate: 2.5000e-04
## Epoch 239/500
## 90/90 - 0s - 1ms/step - loss: 0.0406 - sparse_categorical_accuracy: 0.9906 - val_loss: 0.1077 - val_sparse_categorical_accuracy: 0.9542 - learning_rate: 2.5000e-04
## Epoch 240/500
## 90/90 - 0s - 1ms/step - loss: 0.0412 - sparse_categorical_accuracy: 0.9875 - val_loss: 0.1525 - val_sparse_categorical_accuracy: 0.9459 - learning_rate: 2.5000e-04
## Epoch 241/500
## 90/90 - 0s - 1ms/step - loss: 0.0431 - sparse_categorical_accuracy: 0.9868 - val_loss: 0.2204 - val_sparse_categorical_accuracy: 0.9168 - learning_rate: 2.5000e-04
## Epoch 242/500
## 90/90 - 0s - 1ms/step - loss: 0.0427 - sparse_categorical_accuracy: 0.9885 - val_loss: 0.0972 - val_sparse_categorical_accuracy: 0.9736 - learning_rate: 2.5000e-04
## Epoch 243/500
## 90/90 - 0s - 1ms/step - loss: 0.0452 - sparse_categorical_accuracy: 0.9854 - val_loss: 0.0976 - val_sparse_categorical_accuracy: 0.9570 - learning_rate: 2.5000e-04
## Epoch 244/500
## 90/90 - 0s - 2ms/step - loss: 0.0452 - sparse_categorical_accuracy: 0.9844 - val_loss: 0.0957 - val_sparse_categorical_accuracy: 0.9723 - learning_rate: 2.5000e-04
## Epoch 245/500
## 90/90 - 0s - 2ms/step - loss: 0.0400 - sparse_categorical_accuracy: 0.9903 - val_loss: 0.0919 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 1.2500e-04
## Epoch 246/500
## 90/90 - 0s - 2ms/step - loss: 0.0412 - sparse_categorical_accuracy: 0.9878 - val_loss: 0.0872 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 1.2500e-04
## Epoch 247/500
## 90/90 - 0s - 2ms/step - loss: 0.0360 - sparse_categorical_accuracy: 0.9899 - val_loss: 0.0862 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 1.2500e-04
## Epoch 248/500
## 90/90 - 0s - 1ms/step - loss: 0.0361 - sparse_categorical_accuracy: 0.9917 - val_loss: 0.0953 - val_sparse_categorical_accuracy: 0.9723 - learning_rate: 1.2500e-04
## Epoch 249/500
## 90/90 - 0s - 2ms/step - loss: 0.0389 - sparse_categorical_accuracy: 0.9903 - val_loss: 0.0966 - val_sparse_categorical_accuracy: 0.9764 - learning_rate: 1.2500e-04
## Epoch 250/500
## 90/90 - 0s - 1ms/step - loss: 0.0386 - sparse_categorical_accuracy: 0.9861 - val_loss: 0.0880 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 1.2500e-04
## Epoch 251/500
## 90/90 - 0s - 2ms/step - loss: 0.0388 - sparse_categorical_accuracy: 0.9878 - val_loss: 0.0873 - val_sparse_categorical_accuracy: 0.9639 - learning_rate: 1.2500e-04
## Epoch 252/500
## 90/90 - 0s - 1ms/step - loss: 0.0409 - sparse_categorical_accuracy: 0.9875 - val_loss: 0.0884 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 1.2500e-04
## Epoch 253/500
## 90/90 - 0s - 1ms/step - loss: 0.0394 - sparse_categorical_accuracy: 0.9885 - val_loss: 0.1014 - val_sparse_categorical_accuracy: 0.9695 - learning_rate: 1.2500e-04
## Epoch 254/500
## 90/90 - 0s - 1ms/step - loss: 0.0389 - sparse_categorical_accuracy: 0.9882 - val_loss: 0.0969 - val_sparse_categorical_accuracy: 0.9584 - learning_rate: 1.2500e-04
## Epoch 255/500
## 90/90 - 0s - 2ms/step - loss: 0.0366 - sparse_categorical_accuracy: 0.9892 - val_loss: 0.0847 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 1.2500e-04
## Epoch 256/500
## 90/90 - 0s - 1ms/step - loss: 0.0400 - sparse_categorical_accuracy: 0.9882 - val_loss: 0.0869 - val_sparse_categorical_accuracy: 0.9681 - learning_rate: 1.2500e-04
## Epoch 257/500
## 90/90 - 0s - 2ms/step - loss: 0.0383 - sparse_categorical_accuracy: 0.9892 - val_loss: 0.1001 - val_sparse_categorical_accuracy: 0.9709 - learning_rate: 1.2500e-04
## Epoch 258/500
## 90/90 - 0s - 1ms/step - loss: 0.0366 - sparse_categorical_accuracy: 0.9910 - val_loss: 0.1006 - val_sparse_categorical_accuracy: 0.9709 - learning_rate: 1.2500e-04
## Epoch 259/500
## 90/90 - 0s - 2ms/step - loss: 0.0362 - sparse_categorical_accuracy: 0.9892 - val_loss: 0.0857 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 1.2500e-04
## Epoch 260/500
## 90/90 - 0s - 2ms/step - loss: 0.0360 - sparse_categorical_accuracy: 0.9899 - val_loss: 0.0872 - val_sparse_categorical_accuracy: 0.9695 - learning_rate: 1.2500e-04
## Epoch 261/500
## 90/90 - 0s - 2ms/step - loss: 0.0391 - sparse_categorical_accuracy: 0.9882 - val_loss: 0.1146 - val_sparse_categorical_accuracy: 0.9639 - learning_rate: 1.2500e-04
## Epoch 262/500
## 90/90 - 0s - 2ms/step - loss: 0.0362 - sparse_categorical_accuracy: 0.9899 - val_loss: 0.0929 - val_sparse_categorical_accuracy: 0.9750 - learning_rate: 1.2500e-04
## Epoch 263/500
## 90/90 - 0s - 2ms/step - loss: 0.0365 - sparse_categorical_accuracy: 0.9889 - val_loss: 0.0864 - val_sparse_categorical_accuracy: 0.9639 - learning_rate: 1.2500e-04
## Epoch 264/500
## 90/90 - 0s - 2ms/step - loss: 0.0392 - sparse_categorical_accuracy: 0.9896 - val_loss: 0.1149 - val_sparse_categorical_accuracy: 0.9626 - learning_rate: 1.2500e-04
## Epoch 265/500
## 90/90 - 0s - 1ms/step - loss: 0.0422 - sparse_categorical_accuracy: 0.9851 - val_loss: 0.0863 - val_sparse_categorical_accuracy: 0.9667 - learning_rate: 1.2500e-04
## Epoch 266/500
## 90/90 - 0s - 1ms/step - loss: 0.0358 - sparse_categorical_accuracy: 0.9903 - val_loss: 0.0941 - val_sparse_categorical_accuracy: 0.9736 - learning_rate: 1.2500e-04
## Epoch 267/500
## 90/90 - 0s - 1ms/step - loss: 0.0371 - sparse_categorical_accuracy: 0.9892 - val_loss: 0.0848 - val_sparse_categorical_accuracy: 0.9681 - learning_rate: 1.2500e-04
## Epoch 268/500
## 90/90 - 0s - 2ms/step - loss: 0.0348 - sparse_categorical_accuracy: 0.9910 - val_loss: 0.0907 - val_sparse_categorical_accuracy: 0.9626 - learning_rate: 1.2500e-04
## Epoch 269/500
## 90/90 - 0s - 1ms/step - loss: 0.0371 - sparse_categorical_accuracy: 0.9920 - val_loss: 0.0946 - val_sparse_categorical_accuracy: 0.9723 - learning_rate: 1.2500e-04
## Epoch 270/500
## 90/90 - 0s - 1ms/step - loss: 0.0330 - sparse_categorical_accuracy: 0.9931 - val_loss: 0.0859 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 1.2500e-04
## Epoch 271/500
## 90/90 - 0s - 1ms/step - loss: 0.0358 - sparse_categorical_accuracy: 0.9917 - val_loss: 0.0926 - val_sparse_categorical_accuracy: 0.9723 - learning_rate: 1.2500e-04
## Epoch 272/500
## 90/90 - 0s - 1ms/step - loss: 0.0362 - sparse_categorical_accuracy: 0.9882 - val_loss: 0.1033 - val_sparse_categorical_accuracy: 0.9736 - learning_rate: 1.2500e-04
## Epoch 273/500
## 90/90 - 0s - 1ms/step - loss: 0.0359 - sparse_categorical_accuracy: 0.9906 - val_loss: 0.0881 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 1.2500e-04
## Epoch 274/500
## 90/90 - 0s - 2ms/step - loss: 0.0353 - sparse_categorical_accuracy: 0.9896 - val_loss: 0.0889 - val_sparse_categorical_accuracy: 0.9723 - learning_rate: 1.2500e-04
## Epoch 275/500
## 90/90 - 0s - 1ms/step - loss: 0.0337 - sparse_categorical_accuracy: 0.9931 - val_loss: 0.1168 - val_sparse_categorical_accuracy: 0.9639 - learning_rate: 1.2500e-04
## Epoch 276/500
## 90/90 - 0s - 1ms/step - loss: 0.0360 - sparse_categorical_accuracy: 0.9885 - val_loss: 0.0904 - val_sparse_categorical_accuracy: 0.9750 - learning_rate: 1.0000e-04
## Epoch 277/500
## 90/90 - 0s - 1ms/step - loss: 0.0352 - sparse_categorical_accuracy: 0.9913 - val_loss: 0.0873 - val_sparse_categorical_accuracy: 0.9667 - learning_rate: 1.0000e-04
## Epoch 278/500
## 90/90 - 0s - 1ms/step - loss: 0.0357 - sparse_categorical_accuracy: 0.9910 - val_loss: 0.1033 - val_sparse_categorical_accuracy: 0.9695 - learning_rate: 1.0000e-04
## Epoch 279/500
## 90/90 - 0s - 1ms/step - loss: 0.0364 - sparse_categorical_accuracy: 0.9910 - val_loss: 0.0872 - val_sparse_categorical_accuracy: 0.9667 - learning_rate: 1.0000e-04
## Epoch 280/500
## 90/90 - 0s - 2ms/step - loss: 0.0349 - sparse_categorical_accuracy: 0.9906 - val_loss: 0.0854 - val_sparse_categorical_accuracy: 0.9667 - learning_rate: 1.0000e-04
## Epoch 281/500
## 90/90 - 0s - 2ms/step - loss: 0.0347 - sparse_categorical_accuracy: 0.9920 - val_loss: 0.1036 - val_sparse_categorical_accuracy: 0.9695 - learning_rate: 1.0000e-04
## Epoch 282/500
## 90/90 - 0s - 2ms/step - loss: 0.0330 - sparse_categorical_accuracy: 0.9917 - val_loss: 0.0851 - val_sparse_categorical_accuracy: 0.9695 - learning_rate: 1.0000e-04
## Epoch 283/500
## 90/90 - 0s - 2ms/step - loss: 0.0372 - sparse_categorical_accuracy: 0.9889 - val_loss: 0.0995 - val_sparse_categorical_accuracy: 0.9723 - learning_rate: 1.0000e-04
## Epoch 284/500
## 90/90 - 0s - 1ms/step - loss: 0.0366 - sparse_categorical_accuracy: 0.9899 - val_loss: 0.0969 - val_sparse_categorical_accuracy: 0.9736 - learning_rate: 1.0000e-04
## Epoch 285/500
## 90/90 - 0s - 2ms/step - loss: 0.0354 - sparse_categorical_accuracy: 0.9910 - val_loss: 0.0935 - val_sparse_categorical_accuracy: 0.9750 - learning_rate: 1.0000e-04
## Epoch 286/500
## 90/90 - 0s - 1ms/step - loss: 0.0347 - sparse_categorical_accuracy: 0.9917 - val_loss: 0.0908 - val_sparse_categorical_accuracy: 0.9750 - learning_rate: 1.0000e-04
## Epoch 287/500
## 90/90 - 0s - 1ms/step - loss: 0.0336 - sparse_categorical_accuracy: 0.9917 - val_loss: 0.0877 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 1.0000e-04
## Epoch 288/500
## 90/90 - 0s - 1ms/step - loss: 0.0355 - sparse_categorical_accuracy: 0.9910 - val_loss: 0.1017 - val_sparse_categorical_accuracy: 0.9709 - learning_rate: 1.0000e-04
## Epoch 289/500
## 90/90 - 0s - 1ms/step - loss: 0.0344 - sparse_categorical_accuracy: 0.9917 - val_loss: 0.0879 - val_sparse_categorical_accuracy: 0.9723 - learning_rate: 1.0000e-04
## Epoch 290/500
## 90/90 - 0s - 1ms/step - loss: 0.0361 - sparse_categorical_accuracy: 0.9906 - val_loss: 0.0874 - val_sparse_categorical_accuracy: 0.9723 - learning_rate: 1.0000e-04
## Epoch 291/500
## 90/90 - 0s - 1ms/step - loss: 0.0334 - sparse_categorical_accuracy: 0.9920 - val_loss: 0.0878 - val_sparse_categorical_accuracy: 0.9695 - learning_rate: 1.0000e-04
## Epoch 292/500
## 90/90 - 0s - 1ms/step - loss: 0.0388 - sparse_categorical_accuracy: 0.9889 - val_loss: 0.0888 - val_sparse_categorical_accuracy: 0.9709 - learning_rate: 1.0000e-04
## Epoch 293/500
## 90/90 - 0s - 2ms/step - loss: 0.0368 - sparse_categorical_accuracy: 0.9899 - val_loss: 0.0879 - val_sparse_categorical_accuracy: 0.9681 - learning_rate: 1.0000e-04
## Epoch 294/500
## 90/90 - 0s - 2ms/step - loss: 0.0352 - sparse_categorical_accuracy: 0.9910 - val_loss: 0.0892 - val_sparse_categorical_accuracy: 0.9695 - learning_rate: 1.0000e-04
## Epoch 295/500
## 90/90 - 0s - 1ms/step - loss: 0.0402 - sparse_categorical_accuracy: 0.9882 - val_loss: 0.0892 - val_sparse_categorical_accuracy: 0.9695 - learning_rate: 1.0000e-04
## Epoch 296/500
## 90/90 - 0s - 2ms/step - loss: 0.0372 - sparse_categorical_accuracy: 0.9896 - val_loss: 0.0879 - val_sparse_categorical_accuracy: 0.9667 - learning_rate: 1.0000e-04
## Epoch 297/500
## 90/90 - 0s - 1ms/step - loss: 0.0358 - sparse_categorical_accuracy: 0.9903 - val_loss: 0.0882 - val_sparse_categorical_accuracy: 0.9736 - learning_rate: 1.0000e-04
## Epoch 298/500
## 90/90 - 0s - 2ms/step - loss: 0.0353 - sparse_categorical_accuracy: 0.9903 - val_loss: 0.0912 - val_sparse_categorical_accuracy: 0.9626 - learning_rate: 1.0000e-04
## Epoch 299/500
## 90/90 - 0s - 2ms/step - loss: 0.0314 - sparse_categorical_accuracy: 0.9948 - val_loss: 0.0884 - val_sparse_categorical_accuracy: 0.9736 - learning_rate: 1.0000e-04
## Epoch 300/500
## 90/90 - 0s - 1ms/step - loss: 0.0326 - sparse_categorical_accuracy: 0.9913 - val_loss: 0.0875 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 1.0000e-04
## Epoch 301/500
## 90/90 - 0s - 2ms/step - loss: 0.0343 - sparse_categorical_accuracy: 0.9906 - val_loss: 0.0911 - val_sparse_categorical_accuracy: 0.9653 - learning_rate: 1.0000e-04
## Epoch 302/500
## 90/90 - 0s - 1ms/step - loss: 0.0329 - sparse_categorical_accuracy: 0.9913 - val_loss: 0.0919 - val_sparse_categorical_accuracy: 0.9736 - learning_rate: 1.0000e-04
## Epoch 303/500
## 90/90 - 0s - 1ms/step - loss: 0.0330 - sparse_categorical_accuracy: 0.9924 - val_loss: 0.0929 - val_sparse_categorical_accuracy: 0.9709 - learning_rate: 1.0000e-04
## Epoch 304/500
## 90/90 - 0s - 1ms/step - loss: 0.0346 - sparse_categorical_accuracy: 0.9906 - val_loss: 0.1019 - val_sparse_categorical_accuracy: 0.9709 - learning_rate: 1.0000e-04
## Epoch 305/500
## 90/90 - 0s - 2ms/step - loss: 0.0359 - sparse_categorical_accuracy: 0.9896 - val_loss: 0.0900 - val_sparse_categorical_accuracy: 0.9709 - learning_rate: 1.0000e-04
## Epoch 305: early stoppingEvaluate model on test data
model <- load_model("best_model.keras")
results <- model |> evaluate(x_test, y_test)## 42/42 - 1s - 15ms/step - loss: 0.0980 - sparse_categorical_accuracy: 0.9682
str(results)## List of 2
## $ loss : num 0.098
## $ sparse_categorical_accuracy: num 0.968
cat(
"Test accuracy: ", results$sparse_categorical_accuracy, "\n",
"Test loss: ", results$loss, "\n",
sep = ""
)## Test accuracy: 0.9681818
## Test loss: 0.09801575Plot the model’s training history
plot(history)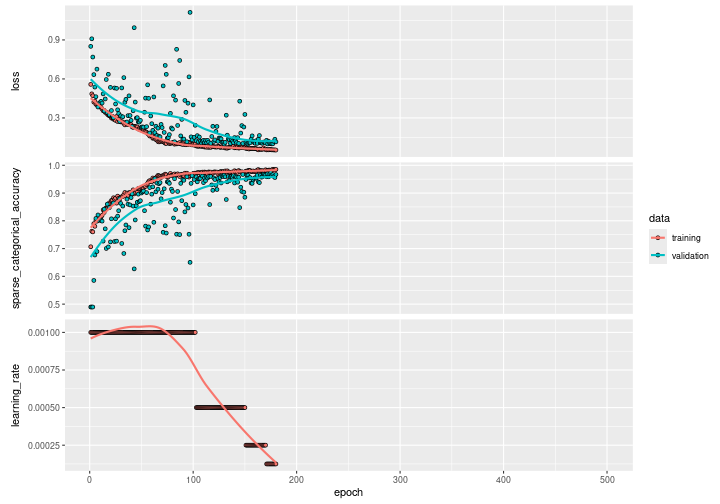
Plot just the training and validation accuracy:
plot(history, metric = "sparse_categorical_accuracy") +
# scale x axis to actual number of epochs run before early stopping
ggplot2::xlim(0, length(history$metrics$loss))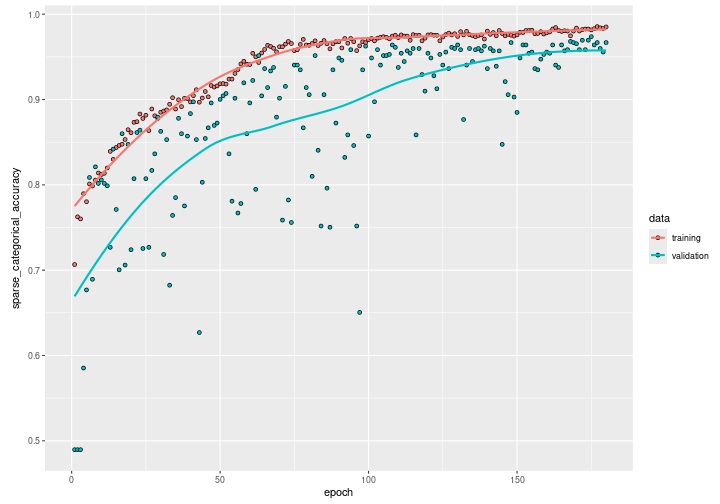
We can see how the training accuracy reaches almost 0.95 after 100 epochs. However, by observing the validation accuracy we can see how the network still needs training until it reaches almost 0.97 for both the validation and the training accuracy after 200 epochs. Beyond the 200th epoch, if we continue on training, the validation accuracy will start decreasing while the training accuracy will continue on increasing: the model starts overfitting.